10.1 Formidable
Zacznijmy od sprawdzonego weterana. Instalacja pakietu wygląda następująco:
npm install formidable
Przeanalizujmy prosty przykład ładowania pliku. Załóżmy, że zainstalowaliśmy już wszystkie pakiety npm i, które wykorzystujemy. Na początku podłączmy te pakiety:
const createError = require('http-errors');
const express = require('express');
const path = require('path');
const fs = require('fs').promises;
const formidable = require('docs/additional_materials/additional-work-with-files/formidable');
const app = express();
Następnie określmy dwie zmienne do przechowywania ścieżek. W pierwszej zmiennej uploadDir przechowujemy ścieżkę, w której zapisany jest plik przy początkowym ładowaniu. W drugiej storeImage ścieżkę, w której przechowywany jest plik ostatecznie.
const uploadDir = path.join(process.cwd(), 'uploads');
const storeImage = path.join(process.cwd(), 'images');
Dlaczego wykorzystujemy dwie ścieżki do przechowywania pliku?
Pierwsza przyczyna, to po załadowaniu może przydać się nam uzupełniające opracowywanie pliku. Na przykład musimy zmniejszyć lub odwrotnie zwiększyć rozmiar obrazu, przerobić go na kwadratowy i tak dalej. Oznacza to, że po opracowaniu przeniesiemy go w nowe miejsce.
Drugą przyczyną jest to, że w trakcie ładowania lub opracowywania pliku może pojawić się nieuwzględniony przez nas błąd. Dodatkowo pakiety na początku często zapisują plik pod jakąś tymczasową nazwą bez rozszerzenia i dopiero po ostatecznym ładowaniu możemy go zmienić. W ten sposób w ścieżce uploadDir znajduje się u nas tymczasowy magazyn i jeżeli będą tam zostawać pliki, oznacza to, że pojawił się u nas jakiś błąd w trakcie ładowania lub opracowywania i należy je koniecznie poprawić, jeśli to możliwe.
Plus tego podejścia polega na tym, że ostateczne pliki można będzie spokojnie usuwać z folderu bez groźby usunięcia czegoś ważnego.
Aby opracować ładowanie plików, musimy utworzyć egzemplarz formidable:
const form = formidable(options);
I rozparserować dane metodą form.parse:
form.parse(req, (err, fields, files) => {
// ...
});
Metoda wywołuje funkcję callback, do której przekazywane są trzy parametry: err błąd, jeśli się pojawił, fields obiekt, który zawiera zwykłe pola formularza i ostatni parametr - files, który może być tablicą, jeśli może ładować się wiele plików lub obiekt, jeśli ładuje się jeden plik.
Powinniśmy pozbyć się funkcji callback. Napiszemy specjalne opakowanie, które będzie zwracało promise z rezultatem parsingu formularza.
const parseFrom = (form, req) => {
return new Promise((resolve, reject) => {
form.parse(req, (err, fields, files) => {
if (err) {
return reject(err);
}
resolve({ fields, files });
});
});
};
Następnie opiszemy program opracowywania trasy /upload dla HTTP metody POST:
app.post('/upload', async (req, res, next) => {
const form = formidable({ uploadDir, maxFileSize: 2 * 1024 * 1024 });
const { fields, files } = await parseFrom(form, req);
const { path: temporaryName, name } = files.picture;
const { description } = fields;
const fileName = path.join(storeImage, name);
try {
await fs.rename(temporaryName, fileName);
} catch (err) {
await fs.unlink(temporaryName);
return next(err);
}
res.json({ description, message: 'Plik załadowany pomyślnie', status: 200 });
});
W nim tworzymy egzemplarz formidable:
const form = formidable({ uploadDir, maxFileSize: 2 * 1024 * 1024 });
gdzie w opcjach pokazujemy:
- uploadDir ścieżkę, w której należy zapisać plik;
- maxFileSize maksymalny rozmiar załadowanych plików to 2 Mb. Zawsze należy sprawdzać rozmiar załadowanych plików.
Następnie parsujemy formularz przy pomocy naszej funkcji parseFrom i otrzymujemy pola tekstowe fields i obiekt z plikiem files.
W naszym przykładzie zakładamy, że nazwa pola z plikiem równa się picture. Przy pomocy destrukturyzacji otrzymujemy ścieżkę, w której znajduje się plik temporaryName i jego oryginalna nazwa name.
const { path: temporaryName, name } = files.picture;
Później nadajemy plikowi nową nazwę. W naszym przypadku zostawiamy go w tym samym miejscu, ale dobrą praktyką jest przypisywanie nowej nazwy do daty lub randomowego hashu, aby przypadkiem jednakowe pliki nie zapisały się jeden na drugim.
const fileName = path.join(storeImage, name);
Przenosimy plik do stałego magazynu:
try {
await fs.rename(temporaryName, fileName);
} catch (err) {
await fs.unlink(temporaryName);
return next(err);
}
Jeśli pojawił się błąd przy przenoszeniu, nie zapomnijmy usunąć pliku tymczasowego.
await fs.unlink(temporaryName);
Jeżeli wszystko zakończyło się sukcesem, na końcu wysyłamy odpowiedź w postaci JSON:
res.json({ description, message: 'Plik załadowany pomyślnie', status: 200 });
Pełen kod naszej aplikacji jest następujący:
const createError = require('http-errors');
const express = require('express');
const path = require('path');
const fs = require('fs').promises;
const formidable = require('docs/additional_materials/additional-work-with-files/formidable');
const app = express();
const uploadDir = path.join(process.cwd(), 'uploads');
const storeImage = path.join(process.cwd(), 'images');
const parseFrom = (form, req) => {
return new Promise((resolve, reject) => {
form.parse(req, (err, fields, files) => {
if (err) {
return reject(err);
}
resolve({ fields, files });
});
});
};
app.post('/upload', async (req, res, next) => {
const form = formidable({ uploadDir, maxFileSize: 2 * 1024 * 1024 });
const { fields, files } = await parseFrom(form, req);
const { path: temporaryName, name } = files.picture;
const { description } = fields;
const fileName = path.join(storeImage, name);
try {
await fs.rename(temporaryName, fileName);
} catch (err) {
await fs.unlink(temporaryName);
return next(err);
}
res.json({ description, message: 'Plik załadowany pomyślnie', status: 200 });
});
const isAccessible = path => {
return fs
.access(path)
.then(() => true)
.catch(() => false);
};
const createFolderIsNotExist = async folder => {
if (!(await isAccessible(folder))) {
await fs.mkdir(folder);
}
};
// catch 404 and forward to error handler
app.use(function(req, res, next) {
next(createError(404));
});
// error handler
app.use((err, req, res, next) => {
res.status(err.status || 500);
res.json({ message: err.message, status: err.status });
});
const PORT = process.env.PORT || 3000;
app.listen(PORT, async () => {
createFolderIsNotExist(uploadDir);
createFolderIsNotExist(storeImage);
console.log(`Server running. Use on port:${PORT}`);
});
Są tutaj dwie funkcje, które zasługują na naszą uwagę. Funkcja isAccessible zwraca logiczne wyrażenie w zależności od tego, czy istnieje folder, a funkcja createFolderIsNotExist tworzy folder, jeżeli on nie istnieje. Gdy otwieramy naszą aplikację, sprawdzamy, czy istnieją foldery uploadDir i storeImage, a jeżeli nie, tworzymy je.
app.listen(PORT, async () => {
createFolderIsNotExist(uploadDir);
createFolderIsNotExist(storeImage);
console.log(`Server running. Use on port:${PORT}`);
});
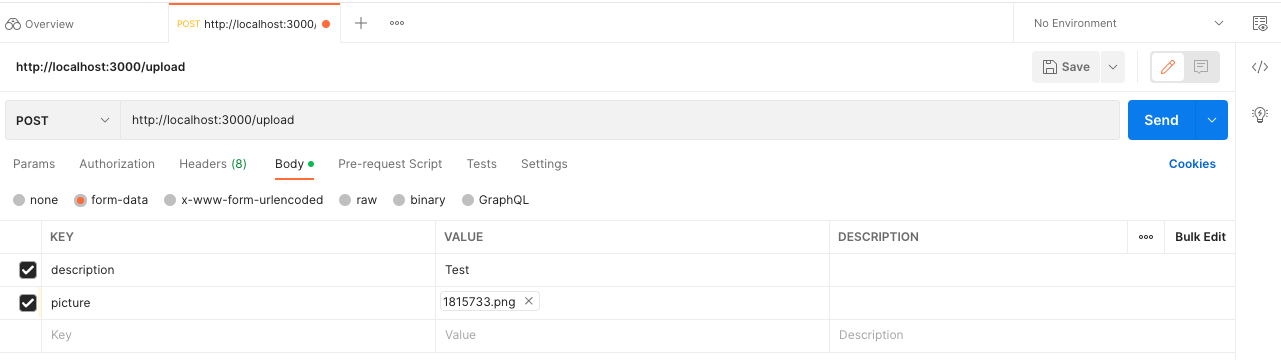
Spróbujmy teraz załadować plik przy pomocy Postman, naśladując pracę formularza w trybie multipart/form-data.
Należy wybrać przy wysyłaniu kodowanie form-data, jak zaznaczono na rysunku. Najważniejsze, aby załadować plik do wysłania go na serwer. W tym trybie klucz należy przekonwertować z typu tekstowego do plikowego.
Jeżeli wszystko zostało wykonane poprawnie, przy wysyłaniu powiadomienia plik będzie ładował się na serwerze i zapisywał w folderze images, a z serwera otrzymamy odpowiedź, jak na obrazku.
Pełen kod przykładu na: Github Gist