1.1 Przykład aplikacji
Po części teoretycznej przejdźmy do praktyki i stworzymy prostą aplikację opartą o express.
Framework Express zapewnia swój generator aplikacji https://expressjs.com/en/starter/generator.html . Generator zorientowany jest na architekturę aplikacji MVC i tworzy następującą strukturę katalogów:

Aby zainstalować template należy użyć polecenia:
npx express-generator --view=ejs simple-express
npx - narzędzie, które jest już w systemie, jeśli zainstalowany został Node.js w wersji wyższej niż 8.x. Pozwala ono wykonywać polecenia innych narzędzi, nie instalując ich globalnie w systemie.
Dalej wskazujemy, że chcemy wykorzystać szablony ejs parametrem --view=ejs
Jako ostatni parametr wskazujemy nazwę aplikacji (i folderu) simple-express.
Aplikacja znajduje się w pliku app.js. Pierwsze, co powinniśmy zrobić, to zmienić var na const w całej aplikacji. Po tej operacji plik app.js powinien wyglądać następująco:
const createError = require('http-errors');
const express = require('express');
const path = require('path');
const cookieParser = require('cookie-parser');
const logger = require('morgan');
const indexRouter = require('./routes/index');
const usersRouter = require('./routes/users');
const app = express();
// view engine setup
app.set('views', path.join(__dirname, 'views'));
app.set('view engine', 'ejs');
app.use(logger('dev'));
app.use(express.json());
app.use(express.urlencoded({ extended: false }));
app.use(cookieParser());
app.use(express.static(path.join(__dirname, 'public')));
app.use('/', indexRouter);
app.use('/users', usersRouter);
// catch 404 and forward to error handler
app.use(function (req, res, next) {
next(createError(404));
});
// error handler
app.use(function (err, req, res, next) {
// set locals, only providing error in development
res.locals.message = err.message;
res.locals.error = req.app.get('env') === 'development' ? err : {};
// render the error page
res.status(err.status || 500);
res.render('error');
});
module.exports = app;
Na początku podłączone są wszystkie niezbędne pakiety, potrzebne do działania aplikacji.
Następnie zażądane są moduły zawierające routing.
const indexRouter = require('./routes/index');
const usersRouter = require('./routes/users');
Później tworzymy egzemplarz aplikacji i ustawiamy wykorzystanie szablonów ejs.
const app = express();
// view engine setup
app.set('views', path.join(__dirname, 'views'));
app.set('view engine', 'ejs');
Następnie pojawią się podłączenia middleware
app.use(logger('dev'));
app.use(express.json());
app.use(express.urlencoded({ extended: false }));
app.use(cookieParser());
Podłącza się logger, opracowywanie JSON i danych z formularzy, a na koniec moduł do pracy z cookie.
Dalej dodawane jest opracowywanie zasobów statycznych z folderu public:
app.use(express.static(path.join(__dirname, 'public')));
Następnie mamy podłączenie routerów w aplikacji:
app.use('/', indexRouter);
app.use('/users', usersRouter);
Pamiętaj, że porządek podłączanego programu pośredniczącego ma znaczenie. Na końcu aplikacji pojawia się opracowywanie błędów. Najpierw zachodzi opracowywanie nieistniejącej ścieżki czyli klasyczny błąd 404.
app.use(function (req, res, next) {
next(createError(404));
});
Następnie z kolei mamy handler błędów które zostaną "wyrzucone" podczas obsługi ścieżek.
app.use(function (err, req, res, next) {
// set locals, only providing error in development
res.locals.message = err.message;
res.locals.error = req.app.get('env') === 'development' ? err : {};
// render the error page
res.status(err.status || 500);
res.render('error');
});
Tutaj zachodzi opracowywanie błędu. Podajemy zmienne message i error do szablonu error.ejs i renderujemy go.
Wewnątrz folderu z naszą aplikacją trzeba zainstalować wszystkie pakiety z pliku package.json poprzez polecenie:
npm i
Teraz dla ułatwienia sobie pracy zainstalujemy pakiet nodemon. Pozwala on wykonywać live reload serwera w trakcie pracy nad kodem. Dodamy wymaganą zależność do devDependencies:
npm i nodemon -D
Następnie w pliku package.json dla uruchomienia aplikacji w trybie deweloperskim dodajemy skrypt start:dev:
"scripts": {
"start": "node ./bin/www",
"start:dev": "nodemon ./bin/www"
},
Uruchomienie aplikacji w trybie deweloperskim będzie następowało przez polecenie:
npm run start:dev
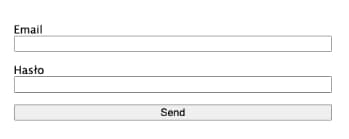
Po uruchomieniu, aplikacja powinna wyglądać następująco po przejściu na adres [localhost:3000](http://localhost:3000) w przeglądarce:
Aplikacja wykonuje renderowanie swojego jedynego szablonu. Samo renderowanie wykonuje się w pliku routingu routes/index.js.
router.get('/', (req, res, next) => {
res.render('index', { title: 'Express' });
});
Przyszedł czas na zmianę naszej aplikacji - dodamy formularz, abyśmy mogli przyjąć dane od użytkownika. Plik index.ejs powinien teraz wyglądać tak:
<!DOCTYPEhtml>
<html>
<head>
<title><%= title %></title>
<link rel="stylesheet" href="/stylesheets/style.css" />
</head>
<body>
<form action="/login" method="POST">
<label for="email">Email</label>
<input type="text" name="email" id="email" />
<label for="password">Hasło</label>
<input type="password" name="password" id="password" />
<button type="submit">Zaloguj się</button>
</form>
</body>
</html>
Dla lepszego wyglądu dodamy następujące style do pliku public/stylesheets/style.css.
form {
display: flex;
flex-direction: column;
width: 400px;
}
input,
button {
margin-bottom: 15px;
}
Potrzebny jest nam program opracowywania dla ścieżki /login, do którego będą przychodzić dane z formularza. Dodajmy go, ale najpierw potrzebujemy nowy szablon response.ejs, gdzie będziemy pokazywać dane z formularza.
<!DOCTYPEhtml>
<html>
<head>
<title><%= title %></title>
<link rel='stylesheet' href='/stylesheets/style.css' />
</head>
<body>
<p>Email: <%= email %></p>
<p>Password: <%= password %></p>
<a href='/'>Wróć do strony główej</a>
</body>
</html>
Teraz w pliku routingu dodamy program opracowywania ścieżki /login.
router.post('/login', (req, res, next) => {
const { email, password } = req.body;
res.render('response', { title: 'Simple express app', email, password });
});
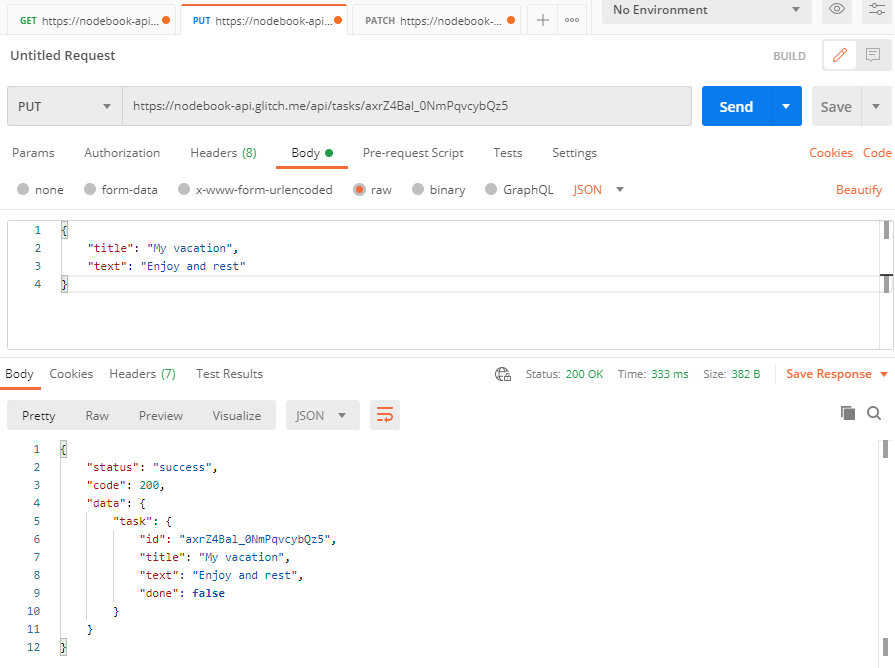
Jest dość uproszczony. Przyjmujemy w nim tylko dwie zmienne i przekazujemy je do renderowania szablonu response.ejs, aby pokazać, że dane zostały otrzymane. Jeżeli wszystko zostało wykonane prawidłowo, wtedy przy wysyłaniu formularza będziemy po prostu widzieli, co wysłaliśmy na serwer

Ten przykład pokazuje przekazanie danych z frontendu do backendu, wykorzystując formularz.
Teraz w pliku routingu user.js dodamy następujący obiekt z kontaktami:
const express = require('express');
const router = express.Router();
const contacts = [
{ id: '1', username: 'Felix', surname: 'Brown', email: 'felix@test.com' },
{ id: '2', username: 'Sonya', surname: 'Redhead', email: 'sonya@test.com' },
{ id: '3', username: 'Conan', surname: 'Barbarian', email: 'conan@test.com' },
];
/* GET users listing. */
router.get('/', function (req, res, next) {
res.json(contacts);
});
module.exports = router;
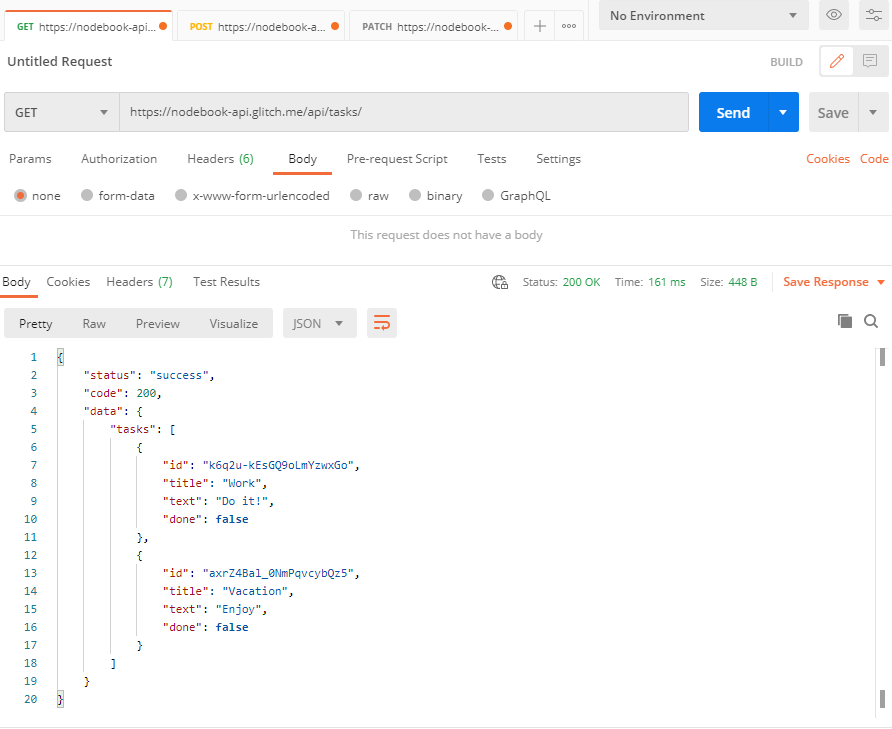
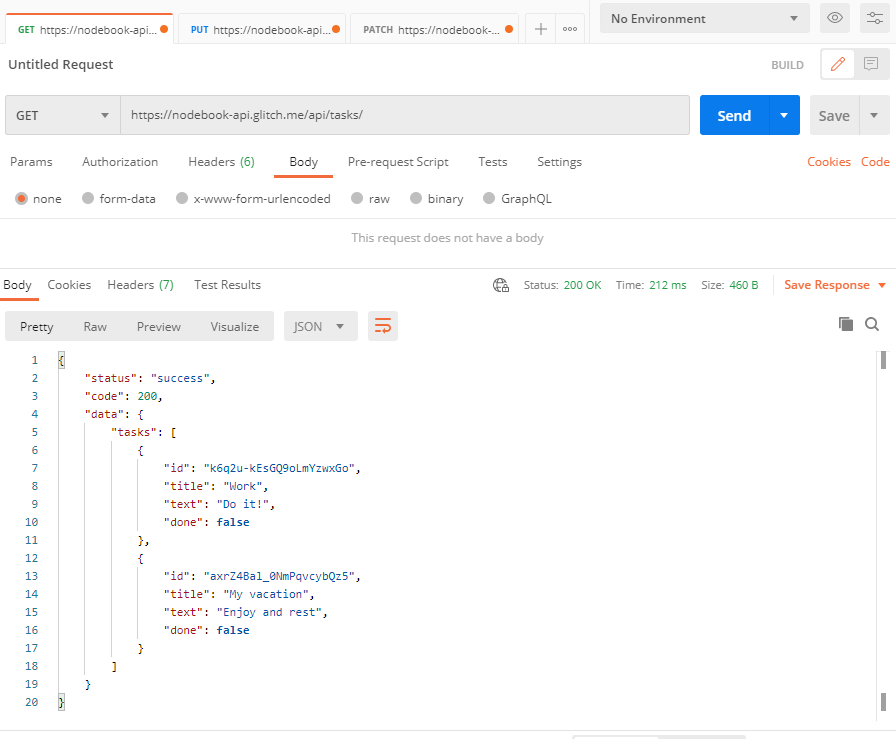
Jeżeli zwrócimy się po ścieżce /users , serwer powinien odesłać nam JSON z tablicą kontaktów.
Dla lepszego odczytywania plików JSON w przeglądarce można wykorzystać następującą aplikację: https://github.com/callumlocke/json-formatter. Dostępna jest ona także jako rozszerzenie dla Chrome. Gdy je zainstalujesz, zawsze będziesz widział dane JSON w czytelnej wersji.
Dodajmy program opracowywania dla otrzymania konkretnego użytkownika zgodnie z jego identyfikatorem:
router.get('/:id', function (req, res, next) {
const { id } = req.params;
const contact = contacts.filter(el => el.id === id);
res.json(contact);
});
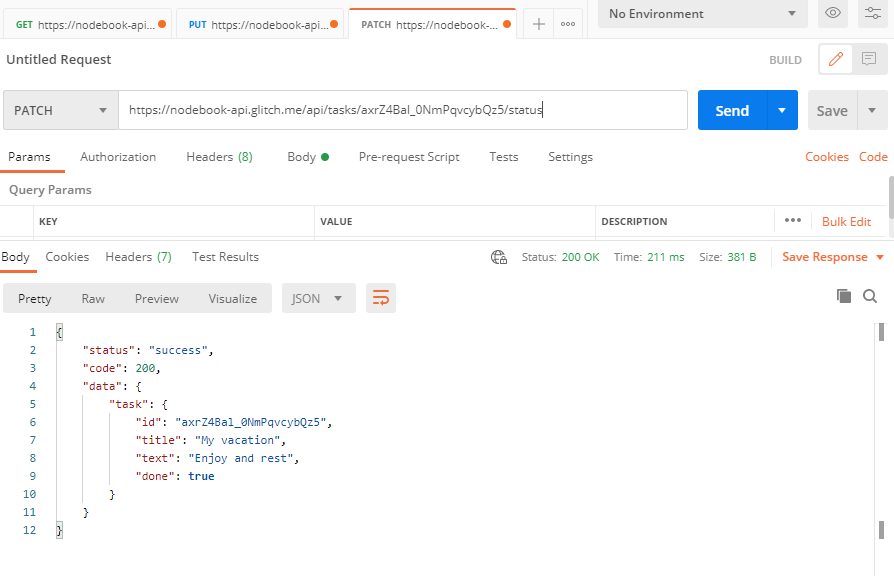
Teraz po zwróceniu się do url /users/2 otrzymujemy dane Rudej Soni:
Taki sposób przekazywania danych będziemy najczęściej wykorzystywać do redagowania i usuwania konkretnego podmiotu zgodnie z jego unikalnym identyfikatorem.
Z pełnym kodem wskazanego przykładu można zapoznać się tutaj: https://glitch.com/~simple-express-nodebook