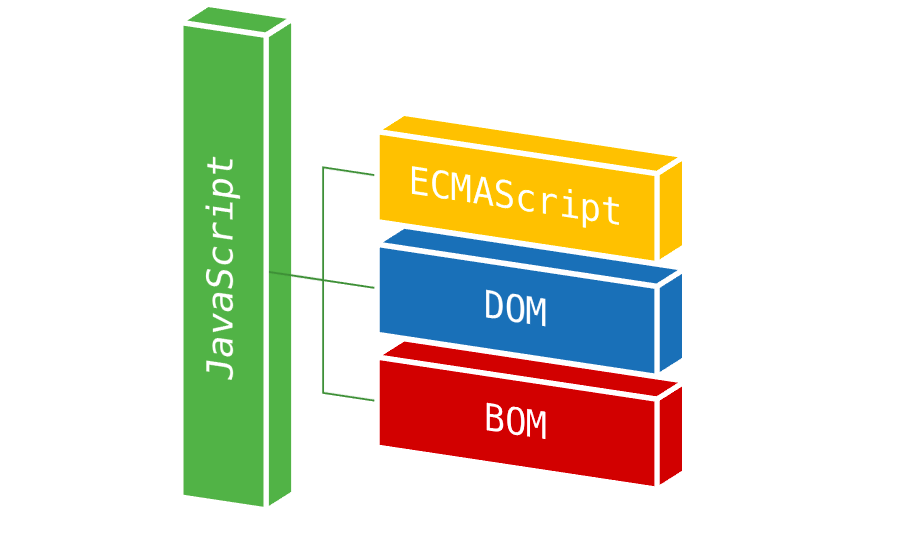
Kiedy pracujemy z przeglądarką, dostępna funkcjonalność składa się z kilku modułów, ponieważ sam JavaScript nie posiada narzędzi do pracy z przeglądarką.
Obiektowy model dokumentu (Document Object Model) to niezależny od języka interfejs do pracy z dokumentami HTML. Zawiera zestaw właściwości i metod, które umożliwiają wyszukiwanie, tworzenie i usuwanie elementów, reagowanie na działania użytkownika i wiele więcej. Oznacza to, że łączy stronę HTML z naszym programem.
DOM jest reprezentacją dokumentu HTML - strukturą zorganizowana hierarchicznie, w której każdy węzeł (node) jest obiektem JavaScript z właściwościami i metodami reprezentującymi część dokumentu HTML. Każdy element w dokumencie, w tym cały dokument, nagłówki, linki, akapity itd są częściami DOM danego dokumentu, więc wszystkie mogą być zmienione przy użyciu kodu JavaScript.
Model obiektowy przeglądarki (Browser Object Model) to niezależny od języka interfejs do pracy z kartą przeglądarki. Zawiera zestaw właściwości i metod, które umożliwiają bezpośredni dostęp do bieżącej karty i szeregu funkcji przeglądarki. Zawiera obiekt do pracy z historią nawigacji, lokalizacją (adresem otwartej strony) i nie tylko.
Dokument HTML i DOM
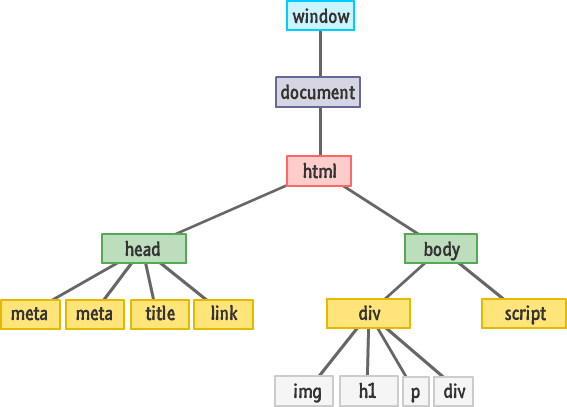
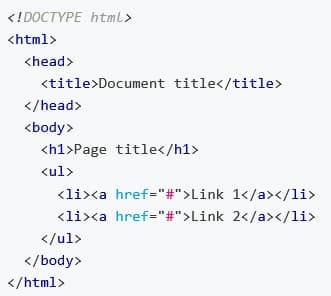
Zgodnie z modelem DOM każdy tag tworzy osobny element (węzeł), każdy fragment tekstu - element tekstowy. Dokument HTML to drzewo hierarchiczne, w którym każdy element (z wyjątkiem "korzeniowego" root) ma tylko jednego rodzica, czyli element, w którym się znajduje. To drzewo składa się z zagnieżdżonej struktury tagów i elementów tekstowych.
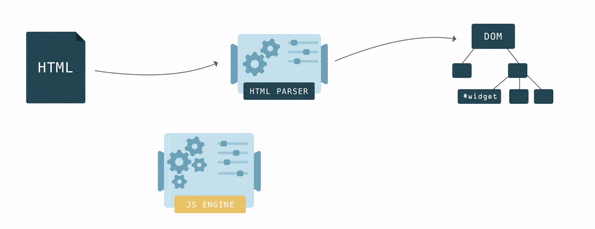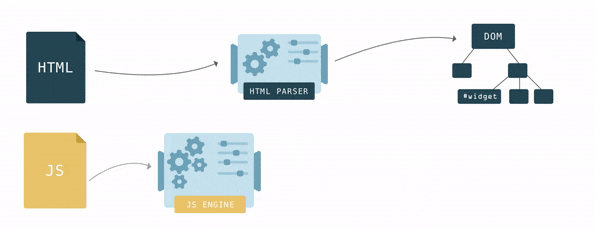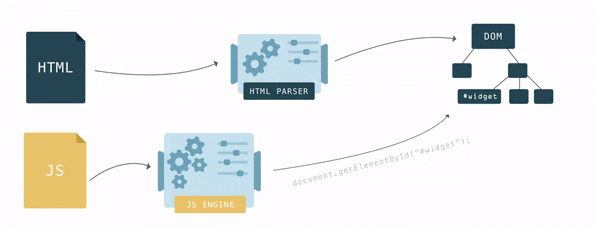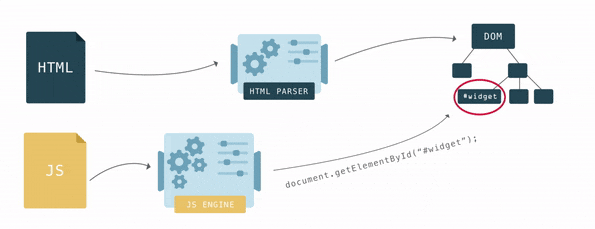
Aby wyświetlić dokument HTML, przeglądarka najpierw konwertuje go do formatu, który rozumie — DOM. Silnik przeglądarki posiada specjalny kod - HTML parser, który służy do konwersji HTML do DOM.
W HTML zagnieżdżenie definiuje relację rodzic-dziecko między elementami. W DOM obiekty są połączone w drzewiastą strukturę danych, fiksując te relacje.
Przeglądarka buduje DOM stopniowo, gdy tylko pojawią się pierwsze linijki, zaczyna parsować kod HTML, dodając węzły do struktury drzewa.
Po utworzeniu drzewa DOM możesz znaleźć w nim element za pomocą JavaScript i wykonać na nim pewne akcje, ponieważ każdy element stanowi obiekt i ma interfejs z wieloma właściwościami i metodami.
Drzewo DOM
Renderujemy drzewo dokumentów HTML za pomocą usługi generator drzewa DOM.
To drzewo ma dwa rodzaje węzłów.
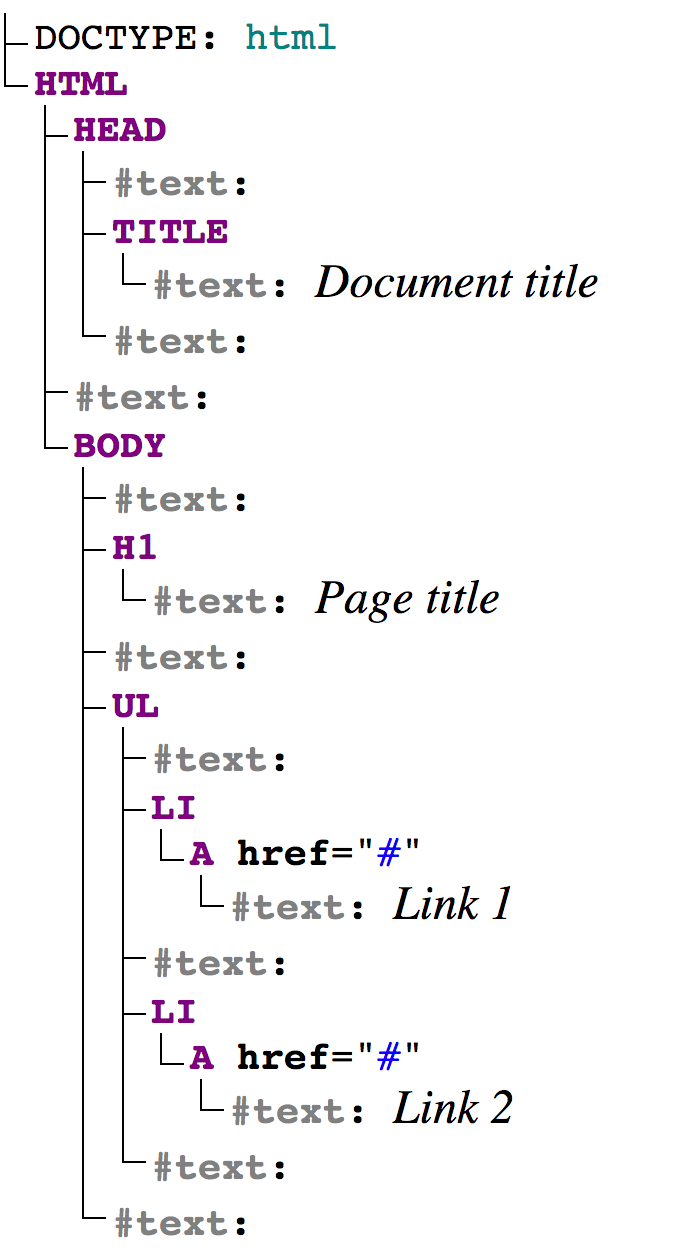
Węzły elementów (element node) są tworzone przez znaczniki, oczywiście niektóre elementy są zagnieżdżane w innych. Tylko one tworzą strukturę drzewa.
Węzły tekstowe (text node) - utworzone przez tekst wewnątrz elementów. Węzeł tekstowy zawiera tylko tekst i nie może mieć dzieci, to znaczy zawsze znajduje się na najniższym poziomie hierarchii. Spacje i podziały wierszy to także węzły tekstowe.
Są wyjątki od tej reguły: spacje przed head są ignorowane, a treść po body nie tworzy elementu, ponieważ przeglądarka kończy DOM wraz z końcem body.
Poruszanie się po drzewie DOM
DOM daje szerokie możliwości pracy z elementami i jego zawartością, ale aby to zrobić, musisz najpierw uzyskać do niego dostęp. Dostęp do DOM zaczyna się od obiektu document, z którego można dostać się do wszystkich zagnieżdżonych elementów DOM
document jest częścią globalnego obiektu window, który jest zawsze dostępny w skrypcie, gdy jest wykonywany w przeglądarce. Podobnie jak alert, console.log, prompt i wiele innych.
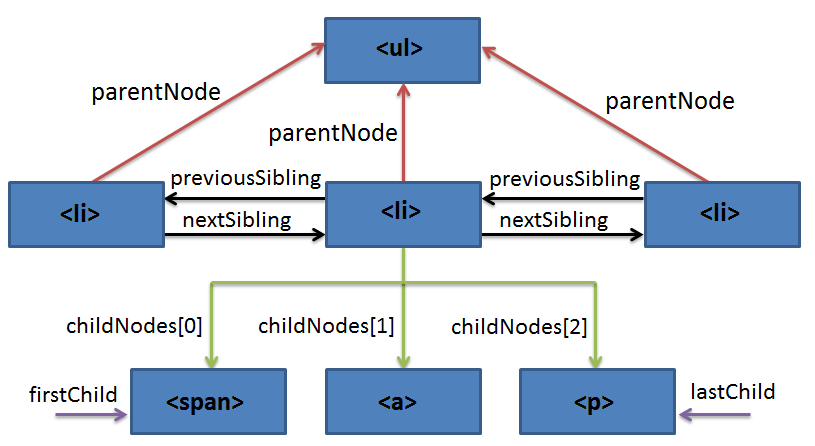
Elementy drzewa DOM są ze sobą hierarchicznie powiązane. Terminy przodek (ancestor), potomek (descendant), rodzic (parent), dziecko (child) i sąsiad (sibling) są używane do opisu relacji.
Najwyższy element nazywa się korzeniem (root node).
Każdy element, poza korzeniem, ma tylko jednego rodzica.
Element może mieć tyle dzieci, ile chcesz.
Sąsiedzi to elementy ze wspólnym rodzicem i nie zagnieżdżone w sobie.
Elementy potomne (dzieci) — elementy, które leżą bezpośrednio wewnątrz bieżącego elementu (pierwsze zagnieżdżenie).
Potomkowie - wszystkie elementy, które leżą wewnątrz obecnego, wraz z ich dziećmi, dziećmi ich dzieci i tak dalej. To znaczy całe "pod-drzewo".
Elementy mają następujące właściwości umożliwiające poruszanie się po tej hierarchii.
elem.parentNode - wybierze rodzica elem.
elem.childNodes - pseudotablica, przechowująca wszystkie elementy potomne, w tym tekstowe.
elem.children - pseudotablica, przechowuje tylko węzły potomne, czyli odpowiadające znacznikom.
elem.firstChild - wybierze pierwszy element potomny wewnątrz elem, w tym węzły tekstowe.
elem.firstElementChild - wybierze pierwszy węzeł potomny wewnątrz elem.
elem.lastChild - wybierze ostatni element potomny wewnątrz elem, w tym węzły tekstowe.
elem.lastElementChild - wybierze ostatni węzeł potomny wewnątrz elem.
elem.previousElementSibling - wybierze element "po lewej stronie" od elem (jego poprzedniego sąsiada).
elem.nextElementSibling - wybierze węzeł "po prawej stronie" od elem (jego następnego sąsiada).
Kolekcje DOM, takie jak childNodes i children są pseudotablicami (NodeList) i nie posiadają większości metod tablicowych.
Wyszukiwanie elementów
Już wiemy, że element DOM to obiekt z właściwościami i metodami. Czas nauczyć się, jak szybko znaleźć element za pomocą dowolnego selektora CSS. Grupa metod elem.querySelector* to nowoczesny standard wyszukiwania elementów. Pozwalają znaleźć element lub grupę elementów za pomocą selektora CSS o dowolnej złożoności.
Najczęściej w miejscu elem znajdziemy po prostu document dzięki czemu szukamy elementów na całej stronie.
element.querySelector(selector);
Stosuje się, gdy trzeba znaleźć tylko jeden, najczęściej unikalny element na przykład po atrybucie id.
Zwraca pierwszy element znaleziony w element, który pasuje do selektora CSS znajdującego się w zmiennej selector.
Jeśli nic nie zostanie znalezione, zwróci null.
element.querySelectorAll(selector);
Jest używany, gdy konieczne jest znalezienie kolekcji elementów, czyli uzyskanie tablicy odniesień do elementów z tym samym selektorem. Przykładem będą wszystkie elementy na liście z klasą menu-item.
Zwraca pseudotablicę wszystkich elementów wewnątrz elementu element, które spełniają wymagania selektora CSS selector.
Jeśli nic nie zostanie znalezione, zwróci pustą tablicę.
Otwórz ten przykład w osobnym oknie i zobacz logi w konsoli programisty.
home
about
gallery
blog
Właściwości i atrybuty
Podczas utworzenia drzewa DOM niektóre standardowe atrybuty HTML stają się właściwościami elementów. Przyjrzyjmy się kilku powszechnie używanym właściwościom.
value - zawiera aktualną wartość elementów formularza. (string)
checked - przechowuje stan pola wyboru lub przycisku radiowego. (boolean)
name - przechowuje wartość określoną w atrybucie HTML name. (string)
elem.textContent zwraca zawartość tekstową wewnątrz elementu. Dostępna jest do odczytu i zapisu. Bez względu na to, co zostanie przekazane do textContent, dane będą zawsze zapisywane jako tekst.
Przykład:
const textEl = document.querySelector('.article-text');
console.log(textEl.textContent); // text inside p.article-text
const titleEl = document.querySelector('.article-title');
titleEl.textContent = 'Welcome to Bahamas!';
Welcome to Hawaii!
Lorem ipsum dolor sit amet consectetur adipisicing elit. Provident quaerat nemo veritatis quasi eius eum aliquid, nobis dolore nisi, magnam eaque iusto, necessitatibus atque laborum quam tempora ducimus dicta ipsam.
Właściwość classList
Właściwość classList przechowuje obiekt z metodami pracy z klasami elementu (tymi które wykorzystujemy do stylowania w CSS).
elem.classList.contains(cls) - zwraca true lub false w zależności od tego, czy element ma klasę cls.
elem.classList.add(cls) - dodaje klasę cls do listy klas elementów.
elem.classList.remove(cls) - usuwa klasę cls z listy klas elementów.
elem.classList.toggle(cls) - jeśli nie ma klasy cls to dodaje ją, jeśli jest to ją usuwa.
Służy do odczytywania i zmiany stylów wbudowanych (inline). Zwraca obiekt CSSStyleDeclaration, który zawiera listę wszystkich właściwości określonych tylko w stylach wbudowanych elementu, (a nie wszystkie reguły CSS dla elementu). W tym obiekcie właściwości są zapisywane w camelCase, to znaczy background-color staje się element.style.backgroundColor itd.
W praktyce stylizowanie elementów odbywa się poprzez dodawanie klas CSS. Właściwość style służy do dodawania pewnego rodzaju stylów dynamicznych, na przykład podczas animacji. W innych przypadkach używanie jej nie będzie dobrą praktyką i utrudni nam stylowanie. Zawsze starajmy się najpierw rozwiązać stylowanie poprzez klasy.
Atrybuty
Elementom DOM odpowiadają tagi HTML, które mają często atrybuty tekstowe. Jeśli atrybut nie posiada swojej własnej określonej właściwości (jak value dla pól input) to dostęp do atrybutów uzyskuje się przy użyciu standardowych metod. Te metody operują na wartości, która jest w HTML.
elem.hasAttribute(name) - sprawdza obecność atrybutu o nazwie name, zwraca true lub false.
elem.getAttribute(name) - pobiera wartość atrybutu i zwraca ją.
elem.setAttribute(name, value) - ustawia atrybut.
elem.removeAttribute(name) - usuwa atrybut.
elem.attributes - właściwość, zwraca obiekt ze wszystkimi atrybutami elementu.
Umożliwia dodanie dowolnego atrybutu do tagu i uzyskanie jego wartości w JavaScript. Możliwość ta jest wykorzystywana w celu uproszczenia pisania kodu, na przykład powiązania danych i znaczników za pomocą unikalnego identyfikatora, wskazania rodzaju akcji na przyciskach itp.
Do pobrania wartości właściwości data-atrybutu używana jest właściwość dataset, po której znajduje się nazwa atrybutu. Oznacza to, że data- jest odrzucane, a reszta nazwy jest zapisywana jako nazwa właściwości obiektu.
Donec id justo. Praesent porttitor, nulla vitae posuere iaculis, arcu nisl dignissim dolor, a pretium mi sem ut ipsum. Curabitur suscipit suscipit tellus. Phasellus gravida semper nisi.
PrzykładEND -------------------------------
Tworzenie i usuwanie elementów
DOM API pozwala nie tylko wybierać lub modyfikować już istniejące, ale także usuwać i tworzyć nowe elementy, a następnie dodawać je do dokumentu.
Tworzenie
document.createElement(tagName);
Tworzy element o nazwie tagName i zwraca link do niego jako wynik wykonania metody. tagName to string wskazujący typ tworzonego elementu. Element jest tworzony w pamięci, nie ma go jeszcze w DOM.
const heading = document.createElement("h1");
console.log(heading);// h1>/h1>
heading.textContent = "This is a heading";
console.log(heading);// h1>This is a heading/h1>
const image = document.createElement("img");
image.src = "https://placeimg.com/640/480/nature";
image.alt = "Nature";
console.log(image);// img src="https://placeimg.com/640/480/nature" alt="Nature" />
Dodawanie
Aby utworzony element został wyświetlony na stronie, musi zostać dodany do już istniejącego elementu w drzewie DOM. Powiedzmy, że dodajemy go do jakiegoś elementu w zmiennej element, możemy skorzystać z następujących metod:
element.append(el1, el2, ...) - dodaje jeden lub więcej elementów pod wszystkimi dziećmi elementu element (czyli na jego "końcu").
element.prepend(el1, el2, ...) - dodaje jeden lub więcej elementów przed wszystkimi dziećmi elementu element (czyli na jego początku).
element.after(el1, el2, ...) - dodaje jeden lub więcej elementów po elemencie element.
element.before(el1, el2, ...) - dodaje jeden lub więcej elementów przed elementem element.
We wszystkich tych metodach el1 i el2 to elementy stworzone np. przy użyciu document.createElement() lub stringi w dowolnej kombinacji i ilości. Stringi są dodawane jako węzły tekstowe.
Przykład -------------------------------
const list = document.querySelector(".usernames");
// Adds an item to the end of the list
const lastItem = document.createElement("li");
lastItem.textContent = "Poly";
list.append(lastItem);
// Adds an item to the beginning of the list
const firstItem = document.createElement("li");
firstItem.textContent = "Ajax";
list.prepend(firstItem);
// Adds a title before the list
const title = document.createElement("h2");
title.textContent = "USERNAMES";
list.before(title);
// Adds a paragraph after the list
const text = document.createElement("p");
text.textContent =
"Lorem ipsum dolor sit amet, consectetur adipisicing elit. Nostrum tenetur assumenda fugiat maxime, soluta
aspernatur quasi nihil in asperiores ad distinctio illo et debitis error iure voluptate numquam maiores
nisi. Lorem ipsum dolor sit amet, consectetur adipisicing elit. Nostrum tenetur assumenda fugiat maxime,
soluta aspernatur quasi nihil in asperiores ad distinctio illo et debitis error iure voluptate numquam
maiores nisi!";
list.after(text);
Mango
PrzykładEND -------------------------------
Jeżeli wstawiany element znajduje się już w DOM, to jest usuwany ze starego miejsca i dodawany do nowego. Wynika to z zasady, że jeden i ten sam element nie może znajdować się jednocześnie w dwóch miejscach.
Usuwanie
elem.remove();
Aby usunąć element, użyj metody remove(). Znajduje się ona na samym elemencie elem, który należy usunąć.
Przykład -------------------------------
const text = document.querySelector('.text');
text.remove();
Article title
Lorem ipsum dolor sit amet consectetur, adipisicing elit. Dolore, ipsa quibusdam! Praesentium accusantium fugiat distinctio quidem minima fugit eos, veniam, nam laboriosam deleniti nisi qui neque explicabo perspiciatis, consectetur non.
Nowoczesne przeglądarki próbują zoptymalizować proces renderowania strony bez interwencji programisty. Każda zmiana drzewa DOM pozostaje jednak kosztowną operacją, dlatego trzeba starać się zminimalizować liczbę wywołań DOM.
Repaint - występuje, gdy zmiany wpłynęły na style, które wpływają na wygląd elementu, ale nie na geometrię. Na przykład opacity, background-color, visibility i outline. Przeglądarka ponownie renderuje element, uwzględniając nowy styl. Sprawdzana jest również widoczność innych elementów, jeden lub więcej może być ukrytych pod zmienionym wyglądem.
Reflow - występuje, gdy zmiany wpływają na treść, strukturę dokumentu, położenie elementów. Pozycjonowanie i wymiary są przeliczane, co prowadzi do przerysowania części lub całości dokumentu. Zmiana rozmiaru jednego kontenera nadrzędnego wpłynie na wszystkie jego dzieci i przodków. Ma znacznie większy wpływ na wydajność niż repaint
Wszystkie powyższe operacje blokują przeglądarkę. Strona nie może wykonywać żadnych innych operacji, gdy trwa reflow lub repaint. Przyczynami mogą być:
Manipulacje drzewa DOM (dodawanie, usuwanie, zmiana, przestawianie elementów)
Zmiana treści, m.in. tekstu w polach formularza
Obliczanie lub modyfikacja właściwości CSS
Dodawanie i usuwanie arkuszy stylów
Manipulacja z atrybutem class
Manipulacje z oknem przeglądarki (zmiana rozmiaru, przewijanie)
Aktywacja pseudoklas (na przykład :hover)
Właściwość innerHTML
Innym sposobem tworzenia elementów DOM i umieszczania ich w drzewie jest użycie stringów zawierających tagi HTML i pozwolenie przeglądarce na wykonanie całej ciężkiej pracy. Takie podejście ma swoje plusy i minusy.
Czytanie
Właściwość innerHTML przechowuje zawartość elementu, w tym znaczniki, jako stringi. Zwracana wartość jest zawsze prawidłowym kodem HTML.
Przykład -------------------------------
const article = document.querySelector(".article");
console.log(article.innerHTML);
const title = document.querySelector(".article .title");
console.log(title.innerHTML);
const text = document.querySelector(".article .text");
console.log(text.innerHTML);
const link = document.querySelector(".article .link");
console.log(link.innerHTML);
Article title
Lorem ipsum dolor sit amet consectetur, adipisicing elit. Dolore, ipsa quibusdam! Praesentium accusantium fugiat distinctio quidem minima fugit eos, veniam, nam laboriosam deleniti nisi qui neque explicabo perspiciatis, consectetur non.
Właściwość innerHTML może służyć zarówno do odczytu jak i zapisu. Jeśli zapiszesz do niej ciąg ze znacznikami HTML, to przeglądarka podczas parsowania stringa zamieni je na odpowiednie elementy i doda je do drzewa DOM.
Przykład -------------------------------
const title = document.querySelector(".article .title");
title.innerHTML = 'New and span class="accent">improved/span> title';
Article title
Lorem ipsum dolor sit amet consectetur, adipisicing elit. Dolore, ipsa quibusdam! Praesentium accusantium fugiat distinctio quidem minima fugit eos, veniam, nam laboriosam deleniti nisi qui neque explicabo perspiciatis, consectetur non.
Jeśli napiszesz pusty ciąg do właściwości innerHTML zawartość elementu zostanie wyczyszczona. To łatwy i szybki sposób na usunięcie całej zawartości.
Dzięki takiemu podejściu, w przeciwieństwie do document.createElement(), nie otrzymujemy odniesienia do utworzonego elementu DOM. To pierwszy krok w kierunku tworzenia szablonów - tworzenia dużej ilości tego samego typu znaczników z różnymi danymi zgodnie z predefiniowanym szablonem. Na przykład jak na liście produktów sklepu internetowego itp.
Jednolite (szablonowe) znaczniki są tworzone z tablicy danych. Podejście polega na iteracji po tablicy i skomponowaniu jednego wiersza ze znacznikami HTML, który następnie zapisujemy w innerHTML elementu.
Przykład -------------------------------
const technologies = ["HTML", "CSS", "JavaScript", "React", "Node"];
const list = document.querySelector(".list");
const markup = technologies
.map((technology) => `li class="list-item">${technology}/li>`)
.join("");
// Check the console, you'll see a single string with HTML tags
console.log(markup);
// Adding all the markup in one operation
list.innerHTML = markup;
Popular technologies
PrzykładEND -------------------------------
Dodanie
Zmiana elem.innerHTML całkowicie usunie i ponownie utworzy wszystkich potomków elementu elem. Jeśli element nie jest początkowo pusty, wystąpią dodatkowe koszty serializacji istniejących znaczników, co źle wpłynie na optymalizację.
Przykład -------------------------------
const article = document.querySelector(".article");
const htmlString = `p class="article-text">Nullam quis ante. Vestibulum dapibus nunc ac augue.
In consectetuer turpis ut velit./p>
a class="link" href="#">Read more.../a>`;
// Replace += with = operator. See the difference?
// Article title is lost because we overwrite element content.
article.innerHTML += htmlString;
Article title
PrzykładEND -------------------------------
Użyj właściwości elem.innerHTML do dodania elementu tylko wtedy, gdy element elem jest pusty lub jeśli chcesz całkowicie zastąpić jego zawartość.
Metoda insertAdjacentHTML()
Nowoczesna metoda dodawania ciągu znaków z tagami HTML przed, po lub wewnątrz elementu. Rozwiązuje problem innerHTML z ponownym serializowaniem zawartości elementu podczas dodawania znaczników do istniejących.
elem.insertAdjacentHTML(position, string);
Argument position to ciąg znaków, pozycja względem elementu elem. Przyjmuje jedną z czterech wartości.
"beforebegin" - przed elem
"afterbegin" - wewnątrz elem, przed wszystkimi dziećmi
beforeend" - wewnątrz elem, po wszystkich dzieciach
"beforebegin" i "afterend" działają tylko wtedy, gdy elem jest już w drzewie DOM.
Łączenie skryptów
Załadowanie i wykonanie skryptu określonego w znaczniku script bez żadnych atrybutów zablokuje przetwarzanie dokumentu HTML i utworzenie DOM. To powoduje problemy.
script src="path-to-script.js">/script>
Gdy przeglądarka napotka taki znacznik, przetwarzanie dokumentu HTML zostaje wstrzymane i rozpoczyna się pobieranie pliku skryptu określonego w atrybucie src. Po załadowaniu skrypt jest wykonywany, a dopiero potem wznawiane jest przetwarzanie HTML. Nazywamy to skryptem "blokującym".
Atrybuty defer i async zostały wprowadzone, aby dać programistom większą kontrolę nad tym, jak ładować skrypty i kiedy je wykonywać.
Atrybut defer
script defer src="path-to-script.js">/script>
Atrybut defer mówi przeglądarce, aby załadować plik skryptu w tle, równolegle z przetwarzaniem dokumentu HTML i tworzeniem DOM. Skrypt zostanie jednak wykonany dopiero po przetworzeniu dokumentu HTML i utworzeniu DOM. Takie skrypty nie blokują utworzenia drzewa DOM i gwarantują wykonanie w kolejności, w jakiej zostały określone w dokumencie HTML, a na dodatek gwarantują, że DOM jest już dla nas dostępny.
Atrybut async
script async src="path-to-script.js">/script>
Załadowanie skryptu z atrybutem async nie blokuje utworzenia DOM, ale jest wykonywane natychmiast po zakończeniu ładowania. Oznacza to, że takie skrypty mogą blokować utworzenie DOM i są wykonywane w dowolnej kolejności co sprawia, że są trudniejsze do prawidłowego zaprojektowania.